
CROSS APPLY as an alternative to UNPIVOT
This morning, I was listening to the inimitable SQL Server Radio podcast, with Matan Yungman and Guy Glantser. They mentioned how Itzik Ben-Gan had documented a great way to turn CROSS APPLY into an extensible UNPIVOT command. I was intrigued, since the CROSS APPLY can be used for so many wierd and wonderful things, and decided to check it out.
I looked at Itzik’s excellent post about the subject over at SQL Server Magazine, and decided to do a blog post of my own, with entirely self-contained code.
CROSS APPLY shares some aspects of CROSS JOIN. A cross join simply combines all the rows from the table on the left of the cross join with all the rows in the table on the right of the cross join. An example of how CROSS JOIN works:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
IF OBJECT_ID('tempdb..#Num1') IS NOT NULL DROP TABLE #Num1; CREATE TABLE #Num1 ( num int NOT NULL ); IF OBJECT_ID('tempdb..#Num2') IS NOT NULL DROP TABLE #Num2; CREATE TABLE #Num2 ( num int NOT NULL ); INSERT INTO #Num1 (num) VALUES (4) , (5) , (6); INSERT INTO #Num2 (num) VALUES (7) , (8) , (9); SELECT #Num1.* , #Num2.* FROM #Num1 CROSS JOIN #num2 ORDER BY #Num1.num; |
The output from the SELECT statement above:
+-----+-----+ | num | num | +-----+-----+ | 4 | 7 | | 4 | 8 | | 4 | 9 | | 5 | 7 | | 5 | 8 | | 5 | 9 | | 6 | 7 | | 6 | 8 | | 6 | 9 | +-----+-----+
As you can see, SQL Server outputs all the rows in #Num2 for each row in #Num1, essentially multiplying the count of rows in each table; since each table has 3 rows, we get 9 (3×3) rows in the output. Extending this example a bit more, lets perform some actions on the columns:
|
1 2 3 4 5 6 |
SELECT [#Num1.num] = #Num1.num , [#Num2.num] = #Num2.num , [x] = #Num1.num * #Num2.num , [+] = #Num1.num + #Num2.num FROM #Num1 CROSS JOIN #Num2; |
The output:
+-----------+-----------+----+----+ | #Num1.num | #Num2.num | x | + | +-----------+-----------+----+----+ | 4 | 7 | 28 | 11 | | 5 | 7 | 35 | 12 | | 6 | 7 | 42 | 13 | | 4 | 8 | 32 | 12 | | 5 | 8 | 40 | 13 | | 6 | 8 | 48 | 14 | | 4 | 9 | 36 | 13 | | 5 | 9 | 45 | 14 | | 6 | 9 | 54 | 15 | +-----------+-----------+----+----+
Now, the common question here would be how to unpivot the “x” and “+” columns. Since CROSS APPLY works similarly to CROSS JOIN in that it applies values from the right side of the CROSS APPLY against each row on the left side of the CROSS APPLY, we can take advantage of the “multiplication effect” of the cross join to generate multiple rows for each row in the above output:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [#Num1.num] = #Num1.num , v.Action , [#Num2.num] = #Num2.num , [ ] = '=' , v.Result FROM #Num1 CROSS JOIN #num2 CROSS APPLY (VALUES ('+', #Num1.num + #Num2.num) , ('x', #Num1.num * #Num2.num) )v(Action, Result); |
The results:
+-----------+--------+-----------+---+--------+ | #Num1.num | Action | #Num2.num | | Result | +-----------+--------+-----------+---+--------+ | 4 | + | 7 | = | 11 | | 4 | x | 7 | = | 28 | | 4 | + | 8 | = | 12 | | 4 | x | 8 | = | 32 | | 4 | + | 9 | = | 13 | | 4 | x | 9 | = | 36 | | 5 | + | 7 | = | 12 | | 5 | x | 7 | = | 35 | | 5 | + | 8 | = | 13 | | 5 | x | 8 | = | 40 | | 5 | + | 9 | = | 14 | | 5 | x | 9 | = | 45 | | 6 | + | 7 | = | 13 | | 6 | x | 7 | = | 42 | | 6 | + | 8 | = | 14 | | 6 | x | 8 | = | 48 | | 6 | + | 9 | = | 15 | | 6 | x | 9 | = | 54 | +-----------+--------+-----------+---+--------+
The code for a more complicated example that performs calculations on the unpivoted columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
/* Demo on how to unpivot data using CROSS APPLY */ USE tempdb; /* create a table to hold test data */ IF OBJECT_ID('#UnpivotTest') IS NOT NULL DROP TABLE #UnpivotTest; CREATE TABLE #UnpivotTest ( ServerName SYSNAME NOT NULL CONSTRAINT PK_UnpivotTest PRIMARY KEY CLUSTERED , DriveCSize BIGINT NOT NULL , DriveCFree BIGINT NOT NULL , DriveDSize BIGINT NOT NULL , DriveDFree BIGINT NOT NULL ) ON [PRIMARY]; /* insert dummy data */ INSERT INTO #UnpivotTest(ServerName, DriveCSize, DriveCFree, DriveDSize, DriveDFree) SELECT si.name , rnd_vals.C , CONVERT(BIGINT, (RAND() * rnd_vals.C)) , rnd_vals.D , CONVERT(BIGINT, (RAND() * rnd_vals.D)) FROM sys.objects si CROSS APPLY ( VALUES (ABS(CHECKSUM(NEWID())), ABS(CHECKSUM(NEWID()))) ) rnd_vals(C,D) WHERE si.name NOT LIKE '#%'; /* show a sample of the raw data */ SELECT top(4) * FROM #UnpivotTest ut; /* UNPIVOT the data without using the UNPIVOT keyword - the CROSS APPLY allows you to reference columns from the table it is APPLYing it's values to. */ SELECT ut.ServerName , ca.Item , ca.Value , Total = CASE WHEN ca.Item LIKE '%Size' THEN (ut.DriveCSize + ut.DriveDSize) ELSE (ut.DriveCFree + ut.DriveDFree) END , ItemPercentOfTotal = CONVERT(DECIMAL(10,2) , CASE WHEN ca.Item LIKE '%Size' THEN ca.Value / (ut.DriveCSize + CONVERT(FLOAT, ut.DriveDSize)) ELSE ca.value / (ut.DriveCFree + CONVERT(FLOAT, ut.DriveDFree)) END * 100 ) FROM #UnpivotTest ut CROSS APPLY ( VALUES ('DriveCSize', ut.DriveCSize) , ('DriveCFree', ut.DriveCFree) , ('DriveDSize', ut.DriveDSize) , ('DriveDFree', ut.DriveDFree) ) ca(Item, Value) ORDER BY ut.ServerName; |
The output looks like:
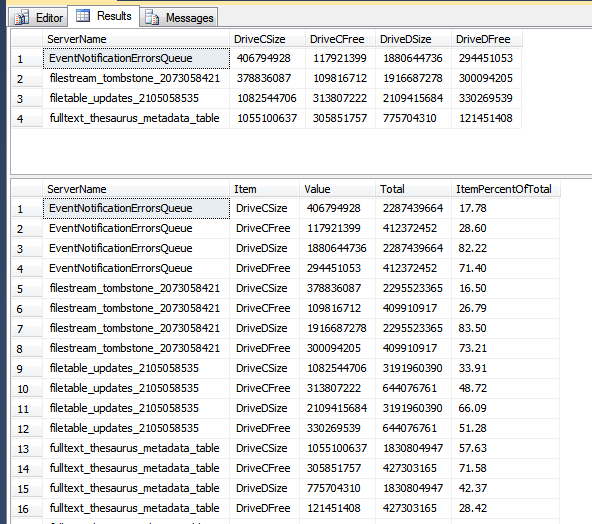
As you can see in the output, we’ve turned the 4 columns, DriveCSize, DriveCFree, DriveDSize, and DriveCFree into 4 rows, and included columns for the total, and a percentage of the total taken by each value.
For cases where you’re dealing with a smallish number of “pivoted” columns, you can re-write the CROSS APPLY to eliminate the CASE statement, and simplify the overall query. For instance,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT ut.ServerName , ca.Item , ca.Value , Total = ca.Value + ca.Complement , ItemPercentOfTotal = CONVERT(DECIMAL(10,2) , ca.Value * 100.0 / (ca.Value + ca.Complement)) FROM #UnpivotTest ut CROSS APPLY ( VALUES ('DriveCSize', ut.DriveCSize, ut.DriveDSize) , ('DriveCFree', ut.DriveCFree, ut.DriveDFree) , ('DriveDSize', ut.DriveDSize, ut.DriveCSize) , ('DriveDFree', ut.DriveDFree, ut.DriveCFree) ) ca(Item, Value, Complement) ORDER BY ut.ServerName; |
The idea here is to use the CROSS APPLY to do the work of the CASE statement by using it to pull the data for the other drives’ “size” or “free” column, to use as the basis for the total and percent of total columns in the final output.